
Proactive Cloud SLA Monitoring: Ensure Uptime & Performance
March 6, 2026|2:45 PM
Unlock Your Digital Potential
Whether it’s IT operations, cloud migration, or AI-driven innovation – let’s explore how we can support your success.
March 6, 2026|2:45 PM
Whether it’s IT operations, cloud migration, or AI-driven innovation – let’s explore how we can support your success.
In today’s fast-paced digital landscape, maintaining optimal cloud service performance is paramount for business continuity and customer satisfaction. Traditional reactive approaches to service level agreement (SLA) breaches are no longer sufficient to meet the demands of modern applications and users. This is precisely where proactive Cloud sla monitoring emerges as an indispensable strategy.
Proactive monitoring shifts the focus from merely reacting to issues after they occur to anticipating and preventing potential problems before they impact users. It involves continuously overseeing cloud resources and services to ensure they consistently meet or exceed defined service level agreements. This preventative SLA monitoring approach is crucial for any organization relying heavily on cloud infrastructure.
Proactive Cloud sla monitoring is a sophisticated methodology designed to anticipate and mitigate potential service disruptions in cloud environments before they escalate into full-blown incidents. Unlike reactive monitoring, which alerts you after an SLA has been breached, proactive monitoring aims to identify early warning signs and predict future performance issues. It leverages advanced analytics and real-time data streams to provide anticipatory cloud service health insights.
This method involves setting up intelligent systems that continuously gather performance data from various cloud components, including virtual machines, databases, networks, and applications. These systems analyze trends, identify anomalies, and trigger alerts based on predefined thresholds, allowing operations teams to intervene swiftly. The goal is to ensure that service performance remains within agreed-upon parameters, providing predictive cloud performance insights.
By employing proactive Cloud sla monitoring, organizations can move beyond simply knowing when something has failed. They gain the ability to understand why a failure might occur and when it is likely to happen, enabling them to take corrective action in advance. This approach is fundamental for future-proof SLA management in complex multi-cloud and hybrid environments.
Embracing proactive Cloud sla monitoring offers a myriad of benefits that extend beyond mere technical compliance, deeply impacting business outcomes. It serves as a cornerstone for maintaining high availability, optimizing costs, and ensuring an exceptional user experience in cloud operations. This strategic shift transforms how organizations manage their cloud infrastructure.
One primary advantage is the significant reduction in downtime, which directly translates to improved business continuity and revenue protection. By catching potential issues early, organizations can prevent service outages that might otherwise lead to lost sales or damaged brand reputation. Proactive measures minimize the window of impact on critical services.
Furthermore, it leads to enhanced customer satisfaction and trust. Users expect seamless experiences, and consistent performance delivered through pre-emptive cloud monitoring helps meet these expectations. Knowing that services are reliably available fosters loyalty and strengthens customer relationships.
From a financial perspective, proactive monitoring can lead to substantial cost savings. Identifying inefficient resource utilization or potential scaling issues early allows for optimized resource allocation, preventing over-provisioning or unexpected burst charges. It helps avoid the costly aftermath of emergency fixes and reputation management.
Compliance and regulatory adherence are also significantly bolstered by this approach. Many industries have strict requirements for service availability and data processing. A robust proactive Cloud sla monitoring system provides the necessary audit trails and performance guarantees to meet these stringent demands, ensuring accountability and transparency.

A successful proactive Cloud sla monitoring guide emphasizes several interconnected components that work in tandem to provide a comprehensive view of cloud health. These elements ensure that monitoring is not only effective but also aligned with business objectives and operational capabilities. Building this strategy requires careful consideration of each part.
The foundational aspect involves meticulously defining what constitutes “good” service performance and establishing clear benchmarks. Without these benchmarks, it is impossible to accurately assess service health or identify deviations from expected behavior. This step sets the stage for all subsequent monitoring activities.
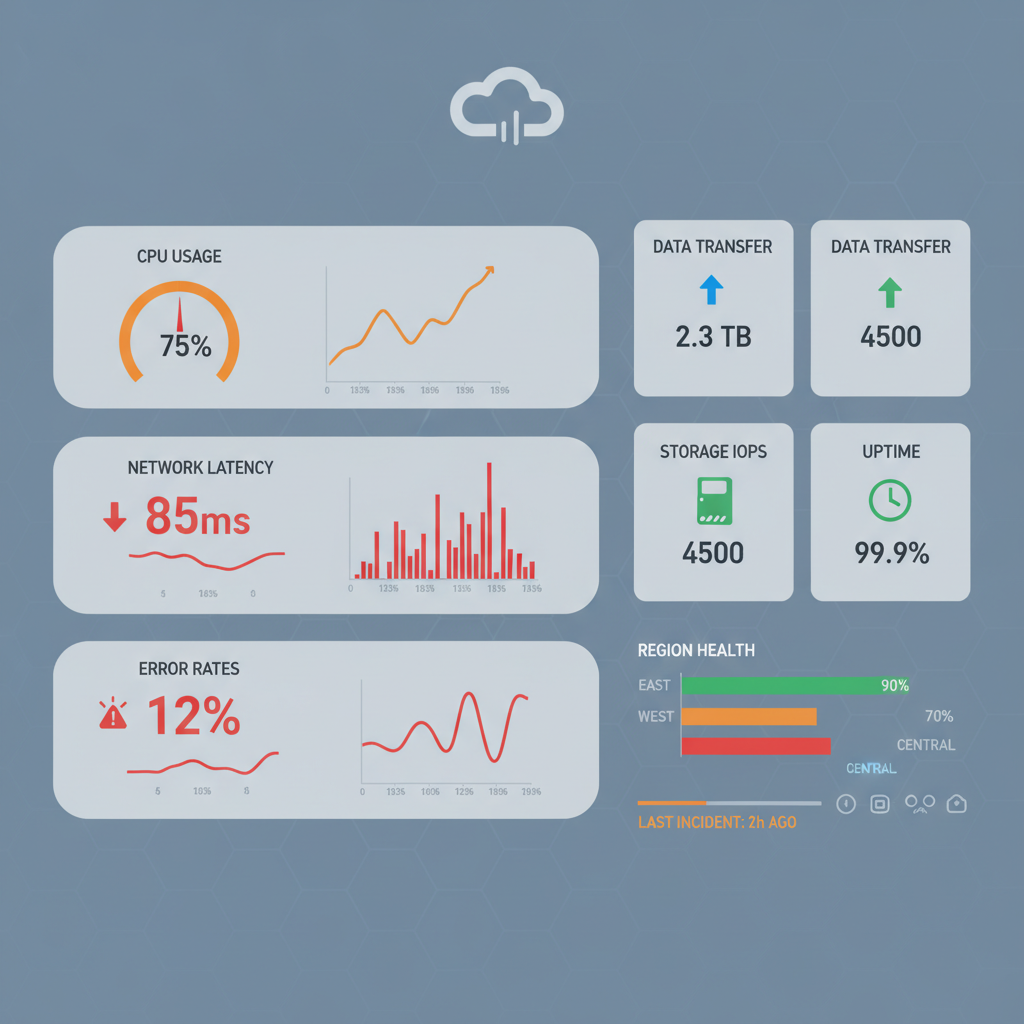
Identifying and tracking the right metrics is fundamental to any proactive Cloud sla monitoring strategy. These metrics must directly correlate with the service level objectives outlined in your SLAs and reflect actual user experience. Focusing on relevant data points avoids noise and highlights truly impactful insights.
Key metrics typically include availability (uptime), latency (response times), throughput (data processed per second), error rates, and resource utilization (CPU, memory, disk I/O). Each of these indicators provides a piece of the puzzle regarding overall system health. Monitoring them continuously helps in early warning SLA tracking.
Modern cloud environments demand sophisticated tools capable of collecting, aggregating, and analyzing vast amounts of data in real time. These tools often incorporate artificial intelligence and machine learning to identify complex patterns and predict future issues. Choosing the best proactive Cloud sla monitoring tools is crucial.
Look for solutions that offer comprehensive dashboards, customizable alerts, and integration capabilities with your existing incident management systems. Features like distributed tracing, log analytics, and synthetic monitoring further enhance visibility across your entire cloud stack. These tools provide the backbone for effective preventative SLA monitoring.
Thresholds are the predefined limits that, when crossed, trigger alerts or automated actions. For proactive monitoring, these thresholds should be dynamic and intelligent, going beyond simple fixed values. They should consider historical performance, seasonal variations, and anticipated load changes.
Instead of just alerting on an SLA breach, intelligent thresholds should warn teams when performance trends suggest a breach is imminent. This predictive capability allows teams to intervene before an actual service degradation occurs. It’s a cornerstone of early warning SLA tracking.
Automation is essential for scaling proactive Cloud sla monitoring across large and complex cloud infrastructures. Automated remediation scripts can fix common issues without human intervention, while AI-powered analytics can detect subtle anomalies that might escape manual review. This makes monitoring more efficient and responsive.
AI and machine learning algorithms can analyze vast datasets to uncover correlations, predict resource needs, and even suggest preventative actions. This significantly enhances the effectiveness of future-proof SLA management, reducing the burden on human operators and increasing the speed of problem resolution.
Implementing effective proactive Cloud sla monitoring requires a structured approach that encompasses planning, tool selection, configuration, and continuous refinement. Following these steps can help organizations establish a robust system for anticipating and addressing cloud service issues. This proactive Cloud sla monitoring guide ensures a systematic deployment.
Begin by thoroughly reviewing all your cloud service level agreements with providers and internal stakeholders. Understand the specific metrics, targets, and penalties associated with each service. This foundational step ensures your monitoring efforts align directly with contractual obligations and business expectations.
Clarify what “downtime” or “performance degradation” means for each service. Document the criticality of each service, as this will influence your monitoring priorities and alert severities. A clear understanding of your SLAs is the bedrock for effective preventative SLA monitoring.
Based on your SLAs, define the specific KPIs that will indicate the health and performance of your cloud services. These KPIs should be measurable, relevant, and actionable. They are the objective measures of whether your services are meeting their defined targets.
Examples include application response time, database query latency, network packet loss, server CPU utilization, and specific API error rates. Ensure these KPIs directly map back to the service commitments you have made or received. This helps establish clear objectives for predictive cloud performance.
Select monitoring tools that offer comprehensive visibility across your specific cloud environment, whether it’s AWS, Azure, Google Cloud, or a hybrid setup. The tools should support real-time data collection, advanced analytics, and customizable alerting. Evaluate tools based on their ability to support your chosen KPIs.
Consider factors like ease of integration, scalability, cost, and the level of detail they provide. Solutions offering AI/ML capabilities for anomaly detection and predictive analytics are particularly valuable for anticipatory cloud service health. The best proactive Cloud sla monitoring solutions will offer broad coverage.
Set up intelligent thresholds for your identified KPIs, ensuring they are calibrated to provide early warnings rather than just post-incident notifications. Configure different alert severities based on the potential impact of a performance deviation. This forms the core of early warning SLA tracking.
Establish clear notification pathways, ensuring the right people are alerted at the right time through appropriate channels (e.g., Slack, email, PagerDuty). Automate the escalation process for critical alerts that remain unaddressed. This ensures rapid response and minimizes potential damage.
Proactive Cloud sla monitoring is not a set-it-and-forget-it task; it requires continuous review and optimization. Regularly analyze your monitoring data, alert history, and incident reports to identify areas for improvement. Adjust thresholds and KPIs as your services evolve or new patterns emerge.
Conduct periodic audits of your monitoring configuration to ensure it remains aligned with changing SLAs, business priorities, and cloud architecture. Gather feedback from operations teams and end-users to refine your strategy. This commitment to continuous improvement is vital for future-proof SLA management.
Achieving truly superior proactive Cloud sla monitoring goes beyond simply deploying tools; it involves cultivating a culture of vigilance and continuous improvement. Adhering to specific best practices can significantly enhance the effectiveness and efficiency of your monitoring efforts. These proactive Cloud sla monitoring tips will help maximize your investment.
One crucial best practice is to integrate your monitoring data with business intelligence tools. This allows stakeholders to understand the direct impact of cloud performance on business objectives, moving beyond purely technical metrics. Such integration fosters better alignment between IT and business goals.
Periodically audit your monitoring configurations, thresholds, and alert rules to ensure they remain relevant and effective. Cloud environments are dynamic, and what worked last month might not be optimal today. These reviews help refine your approach to preventative SLA monitoring.
Review incidents and near-misses to identify gaps in your monitoring coverage or areas where thresholds could be more precise. This iterative process allows you to learn from past events and strengthen your predictive capabilities. Regular auditing is key to maintaining anticipatory cloud service health.
Treat proactive Cloud sla monitoring as an ongoing journey, not a destination. Constantly seek ways to improve your data collection, analysis, and alerting mechanisms. Embrace new technologies and methodologies as they emerge in the cloud monitoring space. This commitment ensures your system evolves with your infrastructure.
Encourage feedback from your operations teams regarding the usability and effectiveness of the monitoring system. Implement suggestions and refine processes to make monitoring more intuitive and actionable. This ensures your proactive Cloud sla monitoring examples remain relevant and impactful.
Invest in comprehensive training for your operations and development teams on how to effectively use the monitoring tools and interpret the data they provide. A powerful monitoring system is only as good as the team operating it. Ensure everyone understands their role in maintaining cloud service health.
Foster a culture where proactive problem-solving is rewarded and sharing insights from monitoring data is encouraged. Empower teams to act on early warnings and implement preventative measures. This collective expertise strengthens your overall future-proof SLA management.
While the benefits of proactive Cloud sla monitoring are clear, organizations often encounter several challenges during implementation and ongoing management. Addressing these hurdles effectively is crucial for realizing the full potential of your monitoring strategy. These challenges require strategic solutions.
One common challenge is the sheer volume and complexity of data generated by modern cloud environments. Sifting through terabytes of logs and metrics to find meaningful insights can be overwhelming. This data deluge can hinder effective early warning SLA tracking if not managed properly.
Another hurdle is the “alert fatigue” that can arise from poorly configured thresholds, leading to an excessive number of non-critical alerts. This can cause teams to overlook genuinely important warnings. Overcoming this requires intelligent tuning of alert parameters.
Integrating various monitoring tools across different cloud providers and on-premises infrastructure can also be complex. Ensuring seamless data flow and a unified view requires robust integration capabilities. The best proactive Cloud sla monitoring solutions offer comprehensive platform support.
To overcome these, organizations should prioritize tool consolidation where possible, leverage AI/ML for intelligent anomaly detection and noise reduction, and invest in a centralized observability platform. Regular review and optimization of alerts, as detailed in this proactive Cloud sla monitoring guide, are also critical.
This section addresses common queries regarding proactive Cloud sla monitoring, offering concise answers to help clarify key aspects of this essential practice. Understanding these fundamentals can enhance your approach to cloud service management.
Proactive SLA monitoring focuses on anticipating and preventing potential issues before they impact service performance or breach an SLA. Reactive monitoring, conversely, alerts you after an SLA has already been violated or a problem has occurred. The former aims to predict, while the latter responds to an event.
It’s essential because it minimizes downtime, enhances user experience, optimizes cloud costs, and strengthens compliance. By identifying and resolving issues before they become critical, businesses can ensure continuity, maintain customer trust, and protect their revenue streams. This approach supports future-proof SLA management.
Key metrics include availability (uptime percentage), response time (latency), error rates, throughput, and resource utilization (CPU, memory, storage I/O). These indicators provide a comprehensive view of cloud service health and highlight potential performance bottlenecks or degradations. They are vital for anticipatory cloud service health.
AI and machine learning can analyze vast datasets to detect subtle anomalies, predict future performance trends, and identify root causes more rapidly than traditional methods. They help reduce alert fatigue by prioritizing critical events and can even automate remediation for common issues, making pre-emptive cloud monitoring more effective.
Thresholds define the acceptable limits for performance metrics. In proactive monitoring, these thresholds are set to trigger alerts before an actual SLA breach occurs, based on trending data or deviations from normal behavior. They serve as early warning signals, enabling timely intervention and preventing service disruption.
While proactive monitoring significantly reduces the likelihood and impact of outages by identifying and addressing potential issues early, it cannot guarantee the prevention of all outages. External factors, unforeseen bugs, or major cloud provider issues can still occur. However, it greatly minimizes risks and accelerates recovery.
Embracing proactive Cloud sla monitoring is no longer a luxury but a fundamental necessity for any organization leveraging cloud services. It represents a strategic shift from merely reacting to problems to actively anticipating and preventing them, safeguarding business continuity and customer satisfaction. By adopting the principles outlined in this proactive Cloud sla monitoring guide, businesses can transform their approach to cloud management.
Implementing robust preventative SLA monitoring, coupled with advanced tools and a commitment to continuous improvement, ensures resilient and high-performing cloud environments. This forward-thinking strategy empowers teams to maintain optimal service levels, drive efficiency, and build enduring trust with users. Proactive monitoring paves the way for truly future-proof cloud operations.

Experience power, efficiency, and rapid scaling with Cloud Platforms!








